

Fast360
First Open Source OCR Model Arena, Specialized in PDF to Markdown
Fast360
First Open Source OCR Model Arena, Specialized in PDF to Markdown
Video: Fast360
First Open Source OCR Model Arena, Specialized in PDF to Markdown
Fast360
SKU: fast360
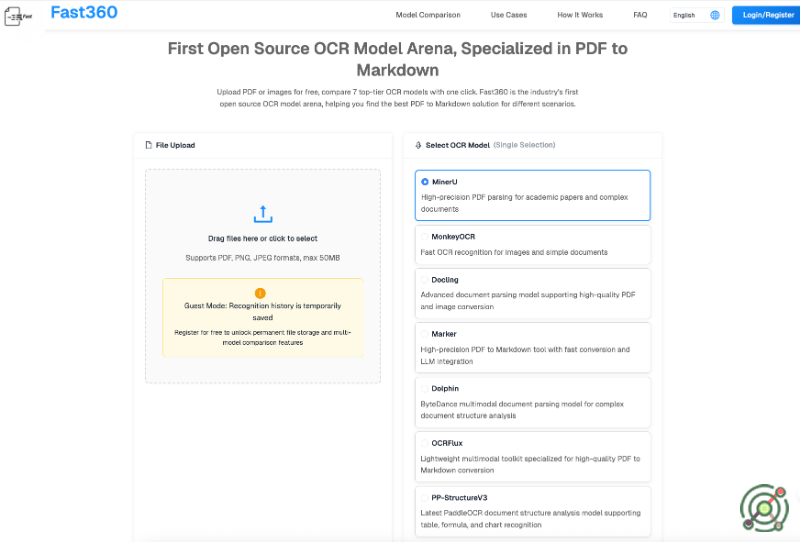
Upload PDF or images for free, compare 7 top-tier OCR models with one click. Fast360 is the industry's first open source OCR model arena, helping you find the best PDF to Markdown solution for different scenarios.
Specializes in extracting clean Markdown from PDFs, removing headers, footers, and other noise.
Academic papers, with good support for LaTeX formulas and multi-column layouts.
Adopts a "layout-first" strategy, analyzing page structure at high speed for excellent table and figure parsing.
Open Source
Free
🧠 Multi-Model Parallel Processing: Upload once and distribute the document to multiple independent OCR engines for parallel processing, significantly shortening the evaluation cycle.
📝 Optimized for Markdown: Focused on generating structured, code-friendly Markdown. We pay special attention to preserving heading levels, lists, tables, code blocks, and LaTeX formulas.
🔬 Covers Diverse Scenarios: From clean text optimized for RAG to preserving complex layouts in academic papers and digitizing handwritten notes, you can test all scenarios in one place.
💸 Free & No Registration Required