

DeepSeek V3
Cost-efficient open-source MoE model rivaling GPT-4o in reasoning and math tasks
DeepSeek V3
Cost-efficient open-source MoE model rivaling GPT-4o in reasoning and math tasks
Video: DeepSeek V3
Cost-efficient open-source MoE model rivaling GPT-4o in reasoning and math tasks
DeepSeek V3
SKU: deepseek-v3
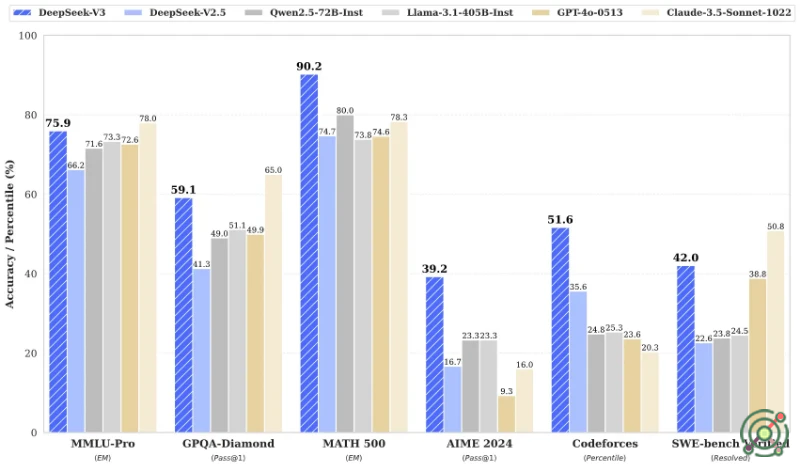
DeepSeek-V3 is a 671-billion-parameter Mixture-of-Experts (MoE) model with 37B parameters activated per token. It excels in coding, mathematics, and multilingual tasks, outperforming leading open-source models like Qwen2.5-72B and Llama-3.1-405B, and matches closed-source models like GPT-4o and Claude-3.5-Sonnet in benchmarks. Trained on 14.8 trillion tokens using FP8 mixed precision, it achieves state-of-the-art efficiency with a 128K context window and 3x faster generation speed compared to its predecessor
Code Generation: Outperforms most models on LiveCodeBench (40.5% pass@1) and Codeforces (51.6 percentile).
Mathematical Reasoning: Achieves 90.2% on MATH-500 and 43.2% on CNMO 2024, surpassing GPT-4o and Claude-3.5.
Education & Research: Scores 88.5% on MMLU, ideal for academic Q&A and technical paper analysis.
Enterprise Automation: Processes multilingual invoices and customer support workflows via API.
Chinese NLP: Dominates C-Eval (86.5%) and C-SimpleQA (64.8%), tailored for Chinese fact-based tasks
Open Source
Freemium
MoE Architecture: 671B total parameters, 37B activated per token, reducing computational costs by 80%.
Multi-Head Latent Attention (MLA): Compresses key-value pairs to reduce memory usage by 40% while maintaining performance.
FP8 Training: First open-source MoE model using FP8 mixed precision, cutting training costs to $5.57M (2.788M H800 GPU hours).
Multi-Token Prediction (MTP): Predicts multiple tokens ahead, improving code generation and long-text coherence.
Dynamic Load Balancing: Auxiliary-loss-free strategy ensures expert utilization without performance trade-offs