
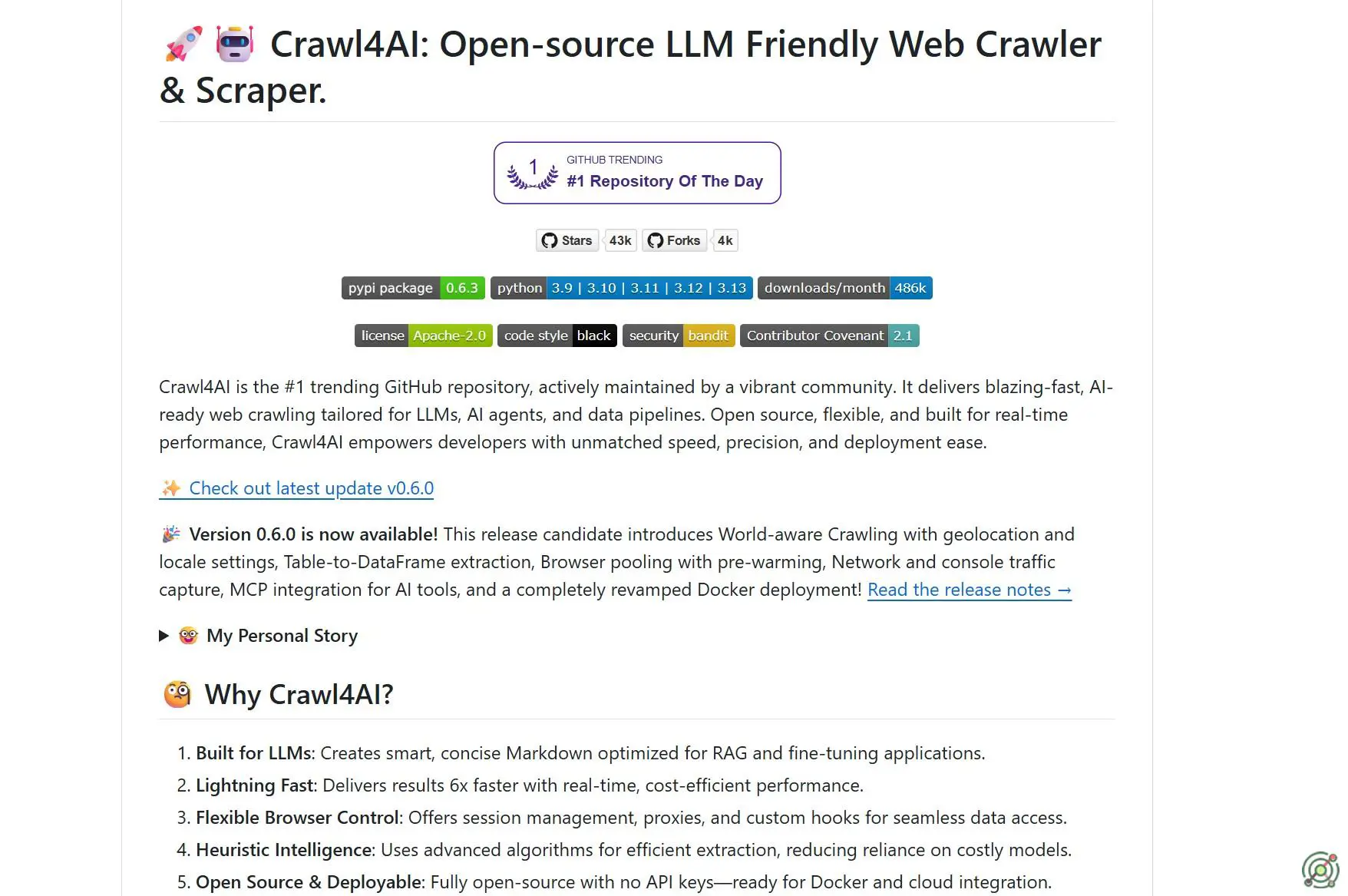
Crawl4AI
An open-source, LLM-friendly web crawler and scraper optimized for AI agents and data pipelines.
Crawl4AI
An open-source, LLM-friendly web crawler and scraper optimized for AI agents and data pipelines.
YouTube Video: Crawl4AI
An open-source, LLM-friendly web crawler and scraper optimized for AI agents and data pipelines.
Crawl4AI
SKU: crawl4ai
Crawl4AI is an open-source, LLM-friendly web crawler and scraper designed to streamline web data extraction for AI agents and data pipelines. It offers features such as asynchronous crawling, structured data output in formats like JSON and Markdown, and integration capabilities with large language models. Crawl4AI supports advanced extraction strategies, including LLM-based methods, and provides tools for handling dynamic content, making it a versatile solution for developers seeking efficient and customizable web scraping solutions.
Extracting structured data from web pages for AI model training.
Integrating real-time web data into AI agents and applications.
Automating data collection for research and analysis.
Handling dynamic web content and complex page structures.
Crawl4AI demonstrates high autonomy through its open-source design, customizable hooks, and robust feature set including parallel crawling, automatic retries, and AI-friendly output formats. It supports structured data extraction via CSS/XPath/LLM methods and handles dynamic content with advanced browser controls (proxies, stealth modes). While requiring initial configuration, its cache system, session reuse, and integration with AI pipelines minimize ongoing human intervention. The tool's ability to process multimedia content and implement chunking strategies further reduces manual preprocessing needs.
Open Source
Contact